With apologies to my family and friends with a genetic predisposition to heart disease, for our next project we applied supervised machine learning classification methods. We were given several topics to choose from, or could pick our own data set to focus on. While an individual project, we were allowed to collaborate in groups. Myself and several classmates, ever interested in using data science to solve the world’s medical problems, used a data set from the ever popular UCI Machine Learning repository on diagnosing heart disease. Dubbing ourselves the “Kardiac Kids” (cute use of the letter K), we each picked different aspects of the problem and collaborated on the cleaning and pre-processing of the data set.
The data set itself is one of the most widely cited in published works and is from a major study by the Cleveland Clinic, together with the Hungarian Institute of Cardiology, Swiss University Hospitals, and Long Beach V.A. Medical Center. After combining the data sets from each location, pre-processing, removing blanks, junk data, etc., we were left with approximately 480 rows and 36 features.
My focus was to try various classification techniques across three different feature sets and compare their performance in classifying patients as either having heart disease or not (binary classification). The three feature sets I used were:
- Prior Research (13 common features used extensively in prior research)
- Feature Selection via Recursive Feature Selection and Model Based Ranking
- American Heart Disease Common Risk Factors
The goal was not such much as to pick a winner, but to get comfortable with the different classification algorithms and various feature selection techniques. The results of the various classification algorithms are shown in the table below.
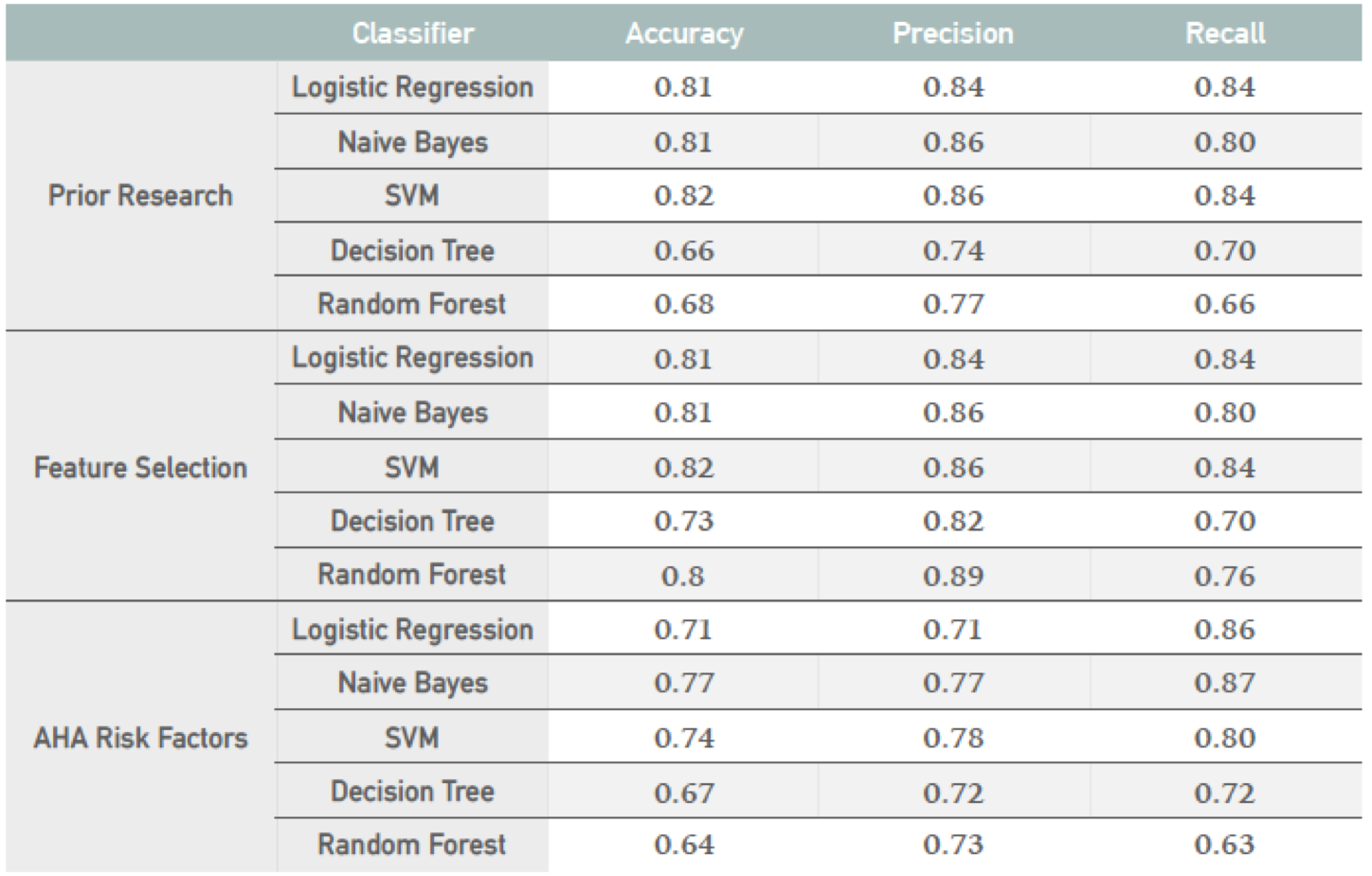
Working on this project, also highlighted another important factor in any data science problem, domain expertise. Not surprisingly, the most accurate predictors of heart disease happened to be some of the most invasive procedures, things like stress tests and cauterization to inject dye into the blood vessels. Sure, these are highly accurate, as they are intended to be. But they are costly, time consuming, and highly invasive. Medical diagnosis is a phased process, and doctors are willing to sacrifice accuracy upfront, performing more routine tests first, and only referring patients for further invasive testing once the probability of a positive diagnosis increases.